In one of my previous posts, I laid out a plan to solve the Get 1000 game. It turns out that plan was wrong.
My expectiminimax based solution works well for a game with random elements and perfect information, but it is not very useful for a game with imperfect information. Get1000 is played simultaneously by the players, and the opponents choices are hidden until the end of the game.
This meant I had to go back to find a new strategy for solving the game. I decided to try and find the correct brute force way first, and then see if that could be made faster in some way.
Exploring brute force
A solution to the game involves finding a Nash equilibrium from all the pure strategies of the game. A brute force solution could be done by creating a matrix where all pure strategies are pitted against all the other pure strategies.
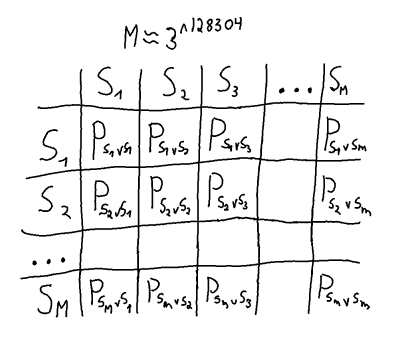
A strategy here refers to a function  which given any game state
which given any game state  gives a Get1000 placement
gives a Get1000 placement  . Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.
. Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.
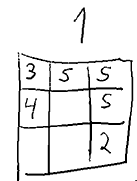
A gamestate can be represented as the current number (in this case 1), the entries in hundres (7), tens (5) and ones (12) as well as the amount of free positions for hundreds (1), tens (2), ones(2).
The total amount of such states is  but in at least
but in at least  the choice is forced. This means there are at most.
the choice is forced. This means there are at most.  relevant states, probably quite a bit fewer.
relevant states, probably quite a bit fewer.
Each state has at most 3 choices, therefore there is an upper bound of  unique pure strategies.
unique pure strategies.
This is of course not that helpful, since a  matrix is enormous, and for each cell in the matrix all possible
matrix is enormous, and for each cell in the matrix all possible  games would have to be played to find the payoff
games would have to be played to find the payoff  for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
Subgame perfection and backwards induction
Modeling this in normal form as above seemed to get me nowhere, I therefore turned to extensive form, and something called subgame-perfect nash equilibria, and backwards induction. In the normal form solution I need to look at all possible strategies. Using subgame perfection, I hoped to get away with only looking at a very small subset.
While this sounds straighforward in theory, I found it quite hard to figure out where my information sets are, and whether I could consider each choice node in Get1000 a subgame. After struggling for a while, I ended up with an extensive form structure looking like this. Players are P1 and P2, and “move by nature” is the dice roll.
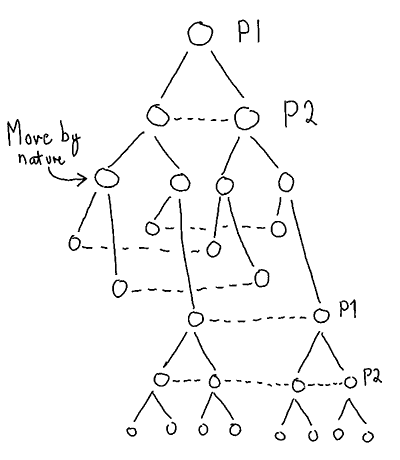
This structure means that only the roots of the tree are subgames, since all other nodes are part of larger information sets.
Attempting backwards induction
The above structure means that it is not practical to naively use subgame perfection and backwards induction to solve the game, but taking inspiration from it could still be useful to get a good strategy.
The algorithm for subgame perfection goes like this:
- Consider the final subgames (those with no further subgames), pick a Nash equilibrium as solution there.
- When considering the next subgames up the tree, the payoffs in the subgames already considered are used to create the payoff matrix.
- Iterate step 2 until the root node of the extensive form tree is reached.
To get something working, I pretend that the other player is at the same state as me always. This means I can only focus on the branches below that state. To keep memory in check i also recalculate payoffs instead of storing the result for each combination of states and games. The final algorithm I ended up with works like this:
- Consider the final subgames and pick a Nash equilibrium as solution.
- When looking at subgames higher up the tree, I use the choices (not payoffs) computed in 1, and use those choices to play out the game. Then I compare end results to get the payoff matrix for that subgame.
- As before, I iterate step 2 until I reach the root node.
This seems intuitively pretty reasonable.
Experimental results
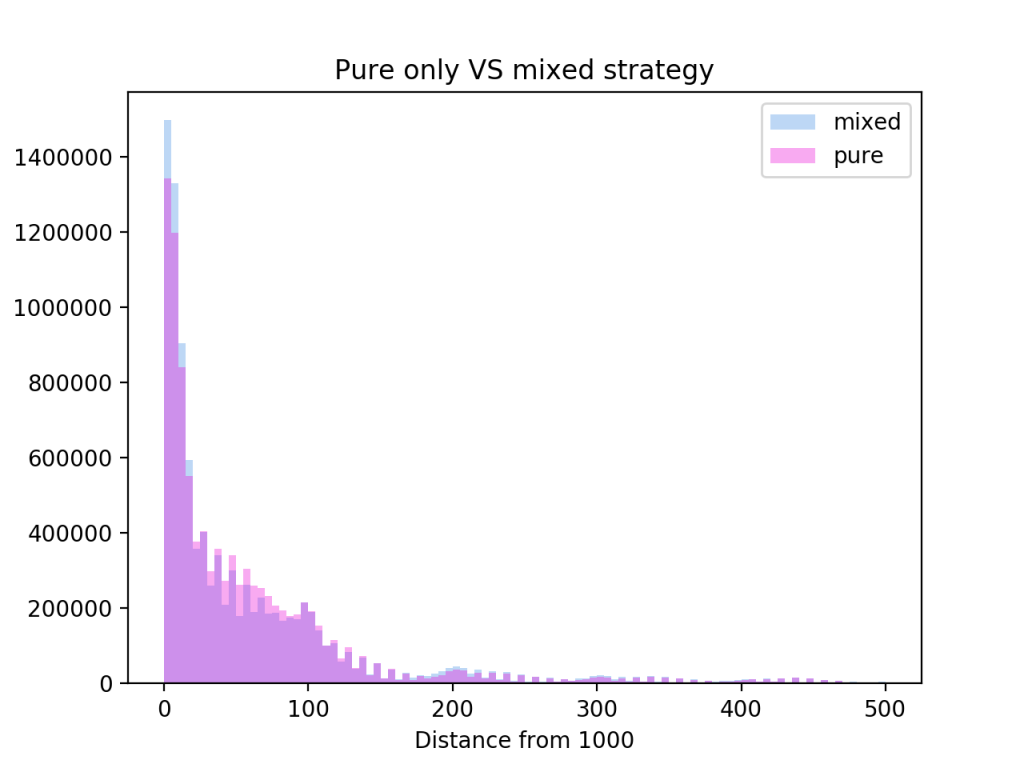
The above method gives me a strategy that partly takes the imperfect information nature of the game into account. At many states it detected mixed strategies that had much higher payoffs compared to the pure versions. The strategies smashes all my previous best strategies by winning 1.75% more games.
At this point, I was not really sure how to approach the game in a better way. In fact I was pretty ready to admin defeat for quite some time. Of course, immediately after i wrote that, I found this thesis, and this report.
Lots of new concepts to learn!