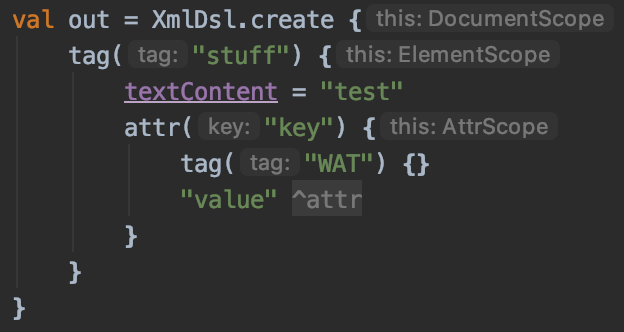
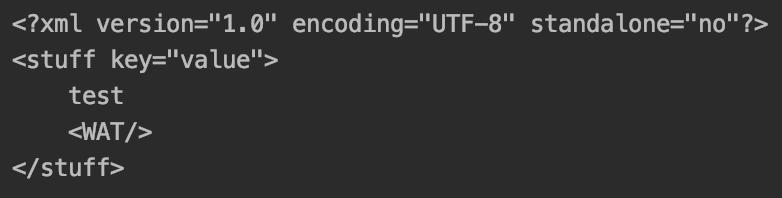
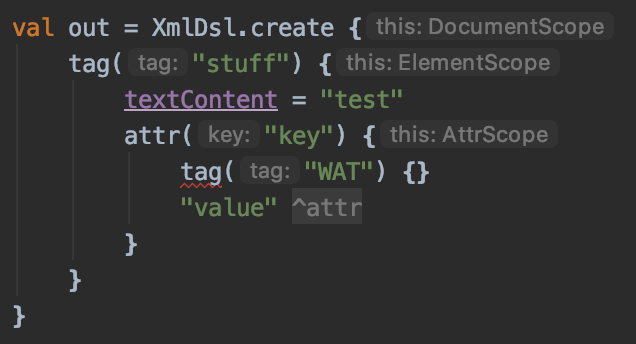
Spring annotation based declarative transactions uses AOP to very easily add transactions around methods. Using it looks like this.
@Transactional
public Stuff createStuff(Input input) {
Stuff stuff = new Stuff(input);
dao.storeStuff(stuff);
dao2.registerStuff(stuff2);
return stuff;
}
Explained very quickly: If the method returns successfully then it commits, if a runtime exception passes the proxy boundary around the method, or if the transaction is marked rollback-only, then the transaction manager will do a rollback of the transaction.
It is incredibly easy to use, and it saves a lot of boilerplate compared to a more procedural approach where commit and rollback calls are specified explicitly. While useful, it comes with the cost of being tied to the scope of the annotated method, along with several other more hidden risks and costs.
Below are several examples of problematic code I have seen caused by annotation based transactions. Similar code examples and tests can be found in this repo on Github.
Catching exceptions in a transaction annotated method
In the method below, it is very easy to think that all errors are handled, and that this method will never throw, but if the transaction is marked as rollback only, this method will throw outside the try catch block. Breaking expectations and causing unexpected errors.
@Transactional
public Stuff createStuff(Input input) {
Stuff stuff = null;
try {
stuff = new Stuff(input);
dao.storeStuff(stuff);
dao2.registerStuff(stuff2);
}
catch(RuntimeException e) {
logger.info("No problem…");
//Do more stuff
}
return stuff;
}
This is much more visible with a explicit transaction scope. I have seen this several times, even by experienced developers. These errors are hard to test for, and when they happen lead to very weird behaviour, since the exception is absolutely not expected where it suddenly occurs.
Order of proxies can change outcome of transaction
It is critical that AOP interceptors are stacked in a sensible order. We usually do not want to commit a transaction, and then get a timeout error from Hystrix. Or have the transaction commit, and then have validation constraints on the Stuff instance fail. Ask yourself. Do you know in which order each annotation will be applied here? Does everyone on your team know?
@Transactional
@HystrixCommand("abc")
@Valid
@OtherAOPstuff
@EvenMoreAOPStuff
public Stuff createStuff(Input input) {
Stuff stuff = new Stuff(input);
dao.storeStuff(stuff);
dao2.registerStuff(stuff2);
return stuff;
}
The order by default is (though due to this Hystrix bug/feature validation will never be applied O_o) :
- Transaction start
- Hystrix
- Validation
- Validation
- Hystrix
- Transaction commit/rollback
It would be nice to have Hystrix outside the Transaction, since that avoids the transaction boundary when the short-circuit is open. This is possible with ordering the AOP interceptors,at the same time, it is important to avoid Validation happening outside the Transaction, since then we might commit and then throw an exception (typically a rollback is wanted if data is invalid).
Nested transactions joins existing transaction by default
This is very nefarious, and I have no idea why nesting transactions does not cause an exception by default.
The example that I think best shows this problem, is when you reuse a method in a service class which uses a transaction further down the call chain. That method uses a transaction to ensure it is rolled back if it throws an exception, but the calling method catches that exception and does some business decision based on the exception.
Now along comes an unsuspecting victim who has a transactional method that wants to use this method for some business purpose.
What happens now, is that the second transaction joins the first. Then an exception is thrown by one of the database queries in moveStuffInDB. That exception passes the first transaction boundary marking the transaction rollback only but is then caught. Processing continues, and then the exception reappears at the last boundary on commit. This means that the semantics of reusedMethod might have been changed a lot, and there is no way createStuff can see from the outside that this will happen.
@Transactional
public Stuff createStuff(Input input) {
Stuff stuff = new Stuff(input);
dao.storeStuff(stuff);
reused.reusedMethod(stuff.getInfo());
return stuff;
}
//A method in another class calling another transactional method.
public void reusedMethod(String input) {
try {
deepClass.moveStuffInDB(input);
}
catch(RuntimeException e) {
//Swallow exception and do some action
}
}
//Tx method with several db update calls
@Transactional
public void moveStuffInDB(String input) {
dao.moveStuff(input);
dao2.moveStuff(input);
}
To add to the confusion, use checked exceptions
When a checked exception passes the boundary of an @Transactional annotated method, it does not cause rollback by default (it can be changed in the annotation though). Add Spring Batch, which will also start transactions that a nested transactions will happily join, and transaction outcomes become even more foggy and hard to reason about.
I think using nested transactions usually is a bad idea, and it should be an opt in feature. In the normal case throwing an exception if a transaction within a transaction is encountered seems sensible to me.
Lambdas provide a much better API for transactions
In any language with good support for lambdas, I think it is very natural to do declarative transaction management using them. Spring sort of supports this, but you need to depend on a platformTransactionManager and a TransactionTemplate. This seems weird to me, given that the annotation based transactions does not make you depend on these.
With lambdas, transactions can be done like below (example is using Kotlin). This is declarative, while providing explicit transaction boundaries. It is therefore very easy to catch around the transaction, and the transaction does not have an unclear order when combined with other annotations.
fun createStuff(stuff : Input ) : Stuff {
return doInTransaction { //Explicit tx scope
val stuff = new Stuff(input);
dao.storeStuff(stuff);
dao2.registerStuff(stuff2);
stuff
}
}
fun multipleTransactionsInMethod(stuff : Input ) : Stuff {
val res = doInTransaction {
val stuff = dao.storeStuff(stuff);
stuff;
}
val res2 = doInTransaction {
val stuff = dao2.storeStuff(stuff);
stuff;
}
try {
doInTransaction {
dao.storeStuff(stuff);
}
} catch(e : RuntimeException) {
//Handle stuff
}
}
Along with the previously mentioned advantages, this also makes transactions much more visible, and allows easy inspection of the transaction code by developers.
To be honest I am a bit uncertain how good it is to rely on exceptions passing boundaries to do rollback in the first place, but if that is the chosen way, I think the above approach is much better then annotation based transactions. I am really looking forward to try Exposed, which is an ORM tool from JetBrains that seems to go in this direction.