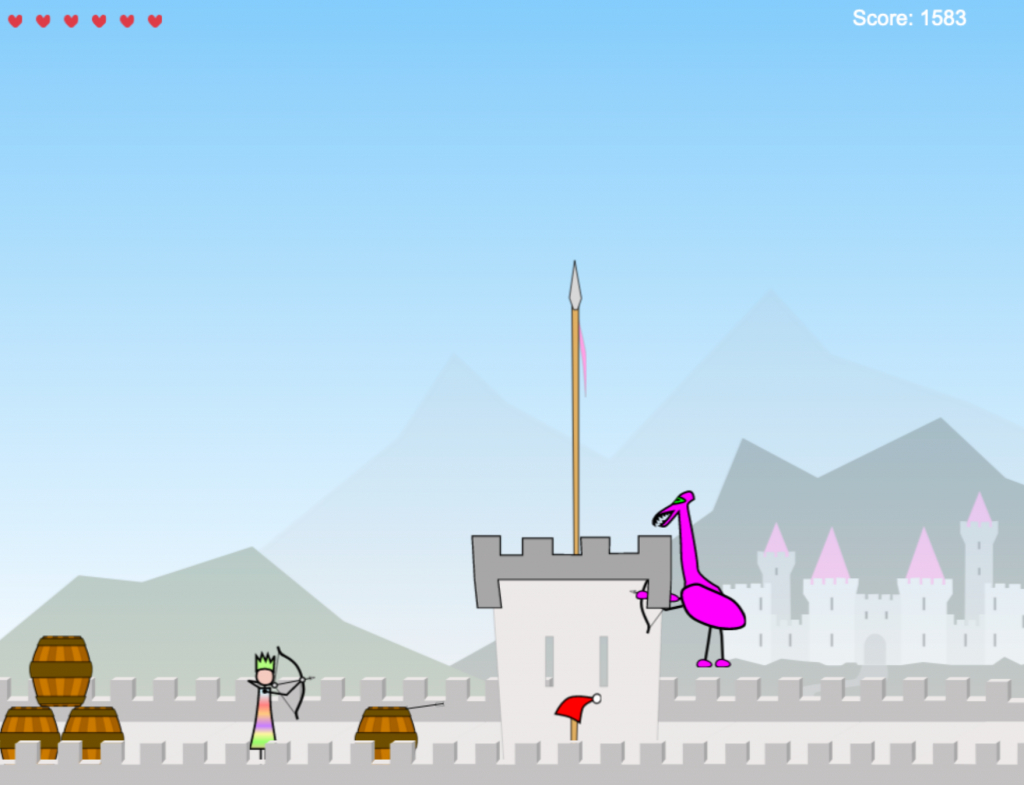
TLDR; I’m writing a coop multiplayer game with my daughter, this is the current result! Works in Firefox and Chrome. Use arrows to move and space to fire. Share a URL to play with a friend.
Some years ago, my daughter figured out I made some computer games, and she even played one of them quite a bit. After a while she wanted something new, and we figured we’ll make a game together. She would draw concepts and come up with ideas, and I would try to make them happen in game.
The initial concepts she drew were these:

We then together made them into vector with some modifications.

Tips on kid friendly vector drawing programs would be very much appreciated, throw me an email or post a comment. We used Sketch, but Sketch is a bit overwhelming and distracting with all its features. I want a program which only have bezier patches and transformations on them, as well as fill, stroke and possibly opacity settings.
Going from concepts to a prototype
I had been wanting to try compile to JS with Kotlin for a while, so I started a project in IntelliJ and quickly threw something together using a plain HTLM5 Canvas.
We drew some more concepts, and after some evenings implementing we had an infinite randomly generated castle, an arrow firing princess, a hyperactive bow carrying giraffe, and a bunch of collision detection bugs (yay for rolling your own).
Wriggling out of hard requirements
After a lot of fun triggering bugs, my daughter came up with some new requirements.
I want to play with my friends, and we should all be princesses!
These are sort of hard to implement, disregarding networking, it would mean a total rewrite of how the world generation and camera worked. It would also need a solution for how to avoid someone getting stuck due to the camera movement of others and so on.

After some bargaining we made some new concepts, and we agreed to add a player controlled cloud, and a bunch of new giraffes.
Adding networking
For me this meant that I would need to add some kind of networking to the game. For browser games, the choices are:
- Communicate with a server using WebSocket and have that relay state, or run the game on the server.
- Negotiate a WebRTC datachannel, and send communication directly between the browsers.
- Have players install a browser extension like netcode.io,and use it instead of WebSocket.
Since the game is cooperative, there is little reason to run the game on a server. Actually I really, really do not want to run the game on server, for a bunch of reasons, mostly for abuse and scaling troubles.
Using a server as a relay of state or input is also a bit funky, since it will introduce a lot of unnecessary latency. Since I am also willing to sacrifice some poor kids behind a symmetric NAT, I decided for option 2 and I have not regretted that.
I was cautious about doing this initially, since I had read this Gaffer on Games post which deemed WebRTC too complex, though that was in the context of server based architectures.
Having some more experience with WebRTC now, I agree a bit about the complexity, though I think it has gotten way better, especially with a more stable standard and more complete alternative implementations like rawrtc. I also ♥ how WebRTC abstracts away most of the P2P complications behind a very nice API.
Autorative peer or GGPO?
To share state in the game, I needed to come up with an architecture for networking. Initially I evaluated using something like GGPO, but in the end I chose to go with using the princess peer as an autorative peer, and sync the state to the cloud playing peer continuously, while the cloud peer only sends input. I chose this mostly for simplicity and time constraints. Since the game is cooperative, a lack of fairness is also not really a problem.
For the amount of work i put in, I am very pleased with how the networking worked out. Right now it is not tuned at all, just JSON over the datachannel, but even without tuning and no extra speculative integration, it has worked fairly well.
Where to go from here.
While the game is in a state of continuous updates, I think it is mostly just going to be small changes from now on. Maybe some sound effects and new graphics when we feel like it.
Rendering is currently also quite slow, and takes a lot of the frame budget. I would like to migrate to a framework with a WebGL based renderer. But sadly that seems like quite a bit of work, mostly due to using SVGs for graphics.
For future projects game projects, I will for sure start with a WebGL based framework, or possibly Unity tiny, and raster based images.
That is all for now, go and see how far you can get in our game!

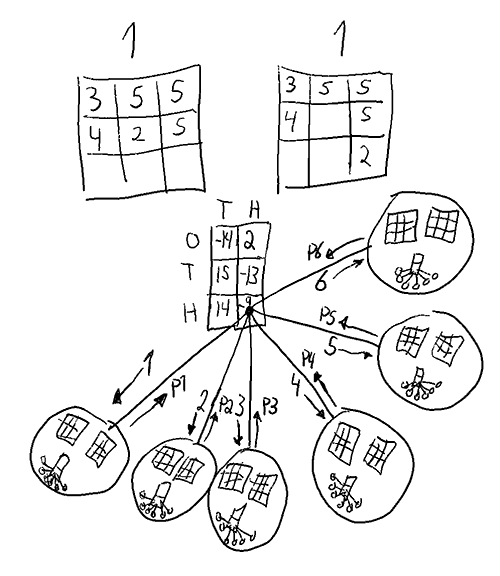
 which given any game state
which given any game state  gives a Get1000 placement
gives a Get1000 placement  . Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.
. Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.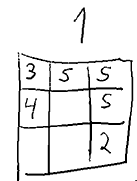
 but in at least
but in at least  the choice is forced. This means there are at most.
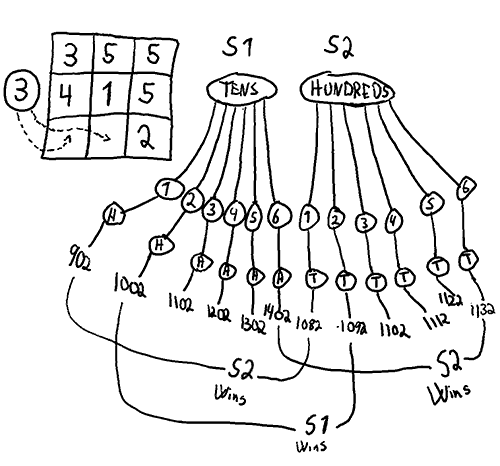
the choice is forced. This means there are at most.  relevant states, probably quite a bit fewer.
relevant states, probably quite a bit fewer. unique pure strategies.
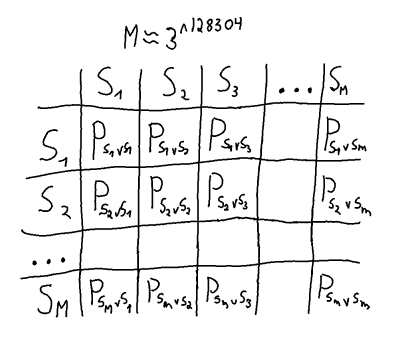
unique pure strategies. matrix is enormous, and for each cell in the matrix all possible
matrix is enormous, and for each cell in the matrix all possible  games would have to be played to find the payoff
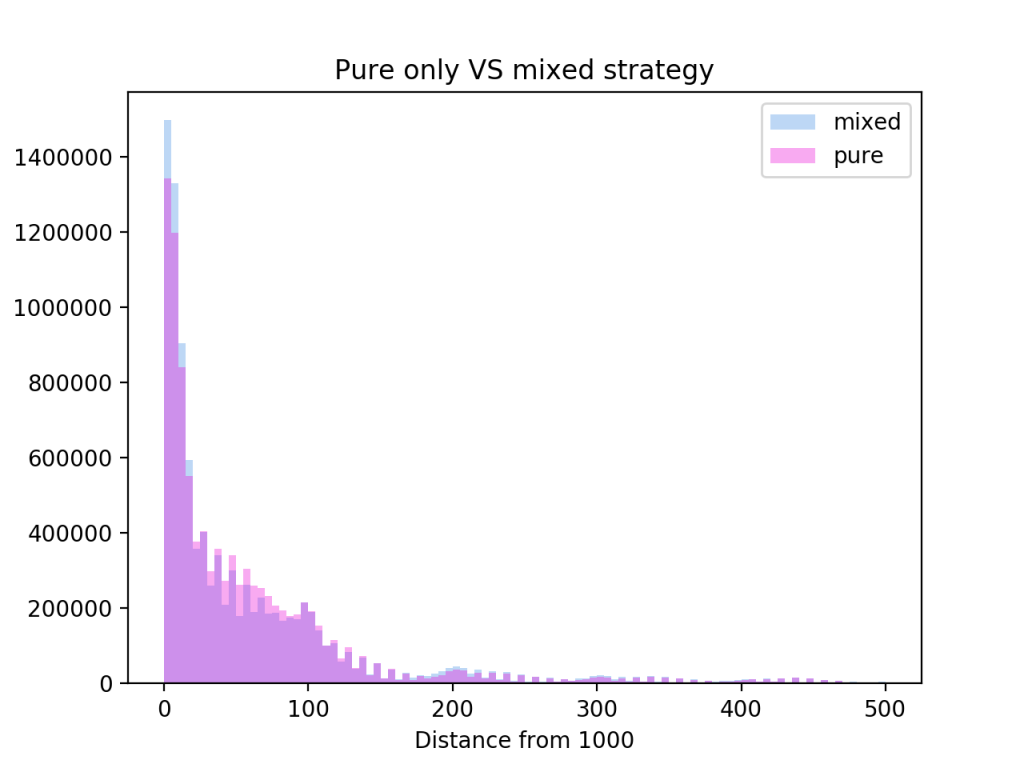
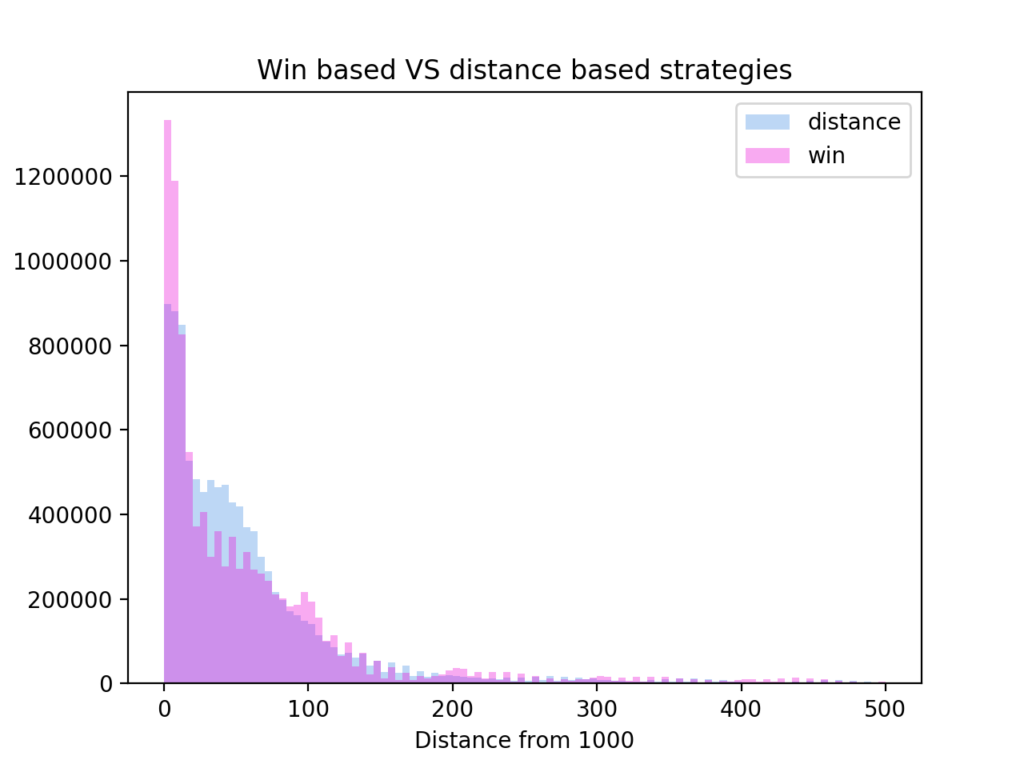
games would have to be played to find the payoff  for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.