No drop bears or reMarkables were harmed making this post, but yours might be if you do nonsense like this. At least take a picture of the reMarkable ssh details before you start and proceed at your own risk.
I really like my reMarkable 2, but the default setup has some shortcomings. The cloud connect thing works nicely, but I want my backups in one place where I am in control. Currently that is my Synology.
My current setup is that my devices connect to the Synology using SSH keys. I do not want my Synology exposed to the world, so my devices are in a Wireguard network with the Synology. The setup of connections is managed using NetBird. To connect my reMarkable I would need to install a NetBird client on it, add a SSH key, then start using rsync to send files to the Synology. Should be easy…
NetBird client
The reMarkable cpu has an arm processor, and runs a version of Linux made for the reMarkable. It turns out that device supports armv7, so the NetBird client can not be the armv8 one, but rather the armv6 one. NetBird had me covered.
TUN
Once installed it seemed to connect fine, but then it stops working, and netbird status said “missing tun” or something like that.
I had experienced this before, so I tried to enable the kernel module tun. Sadly there is no tun on the reMarkable, an issue in reMarkable linux explains this.
Challege accepted! So began an adventure in cross compiling the tun module. Checking out reMarkable Linux got me the branch rm1xx_5.4.70_v1.3.x, which I eventually figured out was the latest release, and the correct branch for this.
Then I needed a cross compiling toolchain. Initially I got a wrong one, and builds would work, but tun would not install on the reMarkable with some really weird errors. Eventually I got the correct toolchain. It can be installed on Ubuntu doing:
sudo apt-get install gcc-arm-none-eabi
With the toolchain in order, Linux build configuration was the next hurdle. At first I struggled with full menuconfig, but a much easier way to configure Linux for the remarkable is to use the existing remarkable 2 (arch/arm/configs/zero-sugar_defconfig) config. I duplicated that and added CONFIG_TUN=m. Then did:
make ARCH=arm CROSS_COMPILE=arm-none-eabi- my-zero-sugar_defconfig make ARCH=arm CROSS_COMPILE=arm-none-eabi- drivers/net/tun.ko
Got the tun.ko and smashed it into the kernel using:
cp tun.ko /lib/modules/5.4.70-v1.3.4-rm11x/kernel/drivers/net/ echo "kernel/drivers/net/tun.ko" >> /lib/modules/5.4.70-v1.3.4-rm11x/modules.dep depmod modprobe tun
And it worked! netbird status said connected!
Dropbear SSH
I added my existing backup key to the reMarkable, and got “SSH error something something”. SSH is also weird, I can not add -vvv to my SSH commands 🤯. ssh -v Dropbear SSH 🤯! I guess I should not have bought that drop bear repellent 25 years ago.
Dropbear SSH seems nice and lightweight. It really wants its own keyformat thing, so I used dropbearkey to generate a new key. Like this:
dropbearkey -f ./id_dropbear -t ed25519 -s 256
Added the printed public key to the Synology, and rsync finally works!
No cron on the reMarkable though; sigh; off to learn systemd timers…


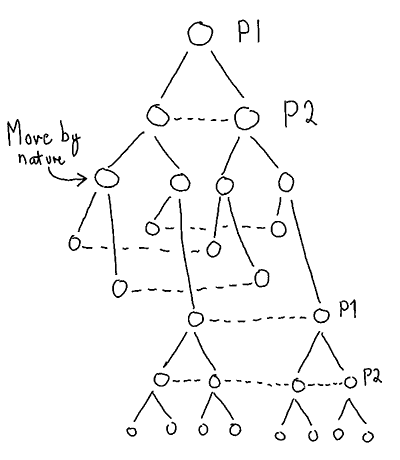
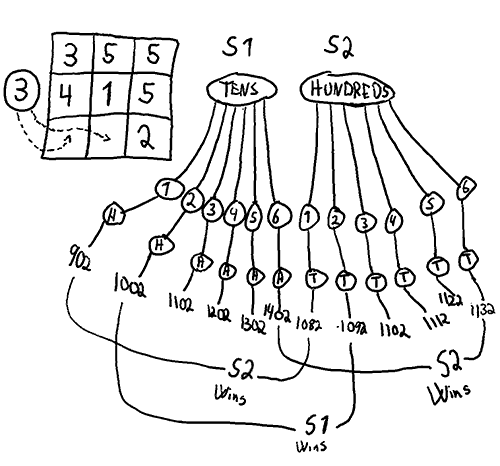
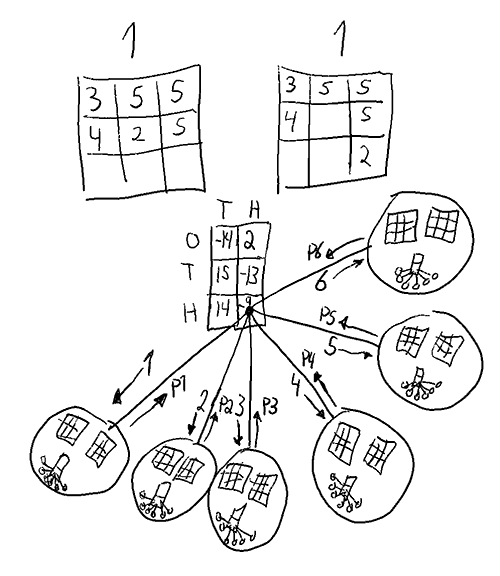
 which given any game state
which given any game state  gives a Get1000 placement
gives a Get1000 placement  . Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.
. Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.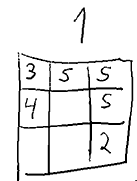
 but in at least
but in at least  the choice is forced. This means there are at most.
the choice is forced. This means there are at most.  relevant states, probably quite a bit fewer.
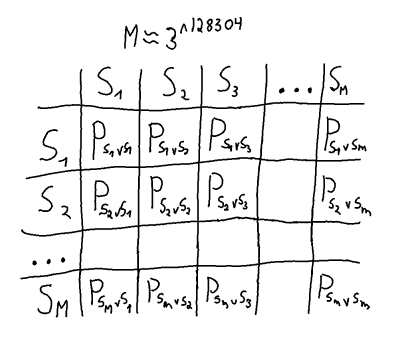
relevant states, probably quite a bit fewer. unique pure strategies.
unique pure strategies. matrix is enormous, and for each cell in the matrix all possible
matrix is enormous, and for each cell in the matrix all possible  games would have to be played to find the payoff
games would have to be played to find the payoff  for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.