For quite some time I have been trying to completely solve the Get 1000 game. More specifically I am trying to find the strategy in a 1 on 1 game of Get 1000 that maximises the chance to win.
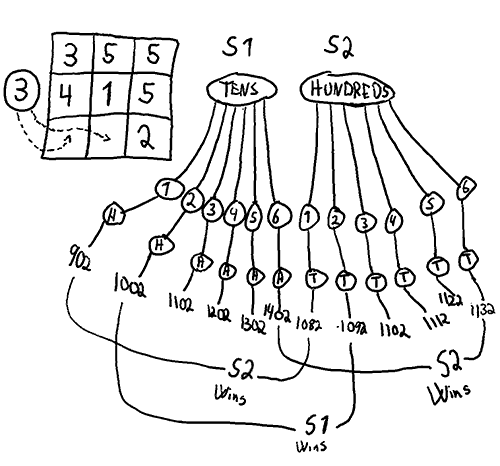
Solving for expected value rather then winning
My initial attempt at solving the game failed spectacularity, since I attempted to solve the game by minimising the average distance of the expected value to a 1000. This is an easy to compute strategy (using a sort of bottom up dynamic programming, where I start with the easy sub-games above, and calculate backwards to the top), but it is the wrong goal. This leads to a strategy minimising the distance to 1000 on average. This interestingly enough differs quite a lot from the goal I wanted to solve, which was to maximise the chance to win any 1 on 1 game.
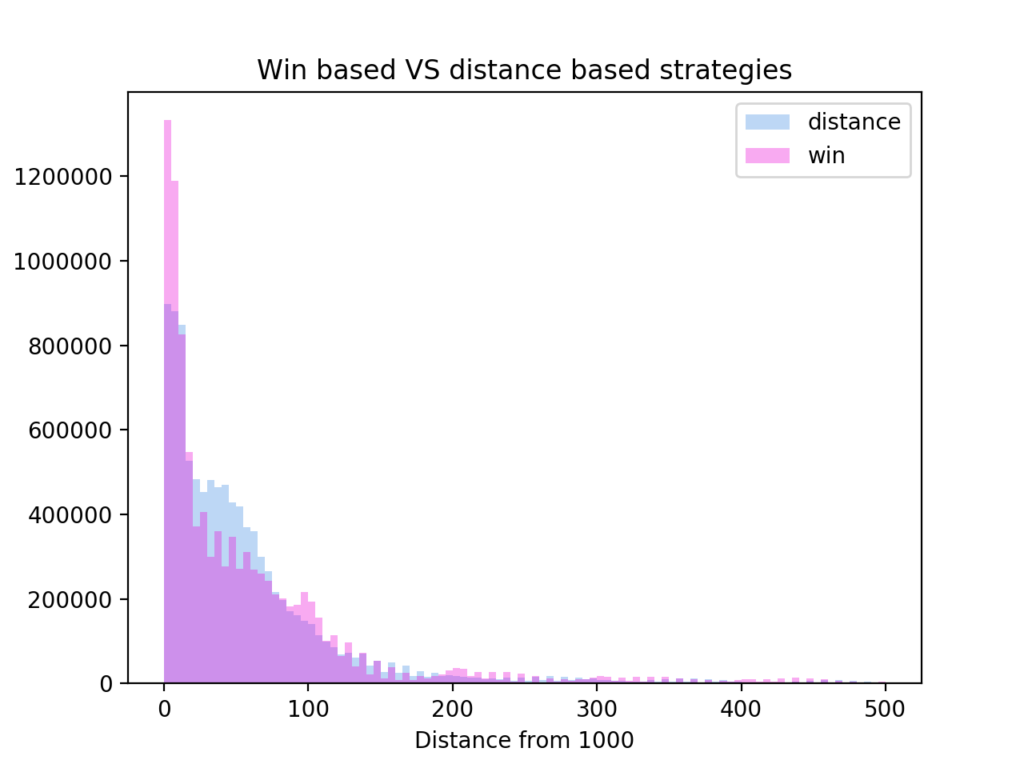
Since Get 1000 is quite small I can calculate how much the two strategies differ by running all possible games. Above is the result of such a calculation. The two strategies draw 41.2% of the time, while the win based wins 30.8% and the distance based wins 28% of the time.
Trouble with situations where choices are equally good
After figuring out I had the wrong goal, I found a way to create a strategy based on wins rather than expected value (this is much harder to compute, even using the same bottom up approach, since it is not possible to collapse results to an average, and ever growing lists of results must be compared). These strategies I suspect are very close to optimal, but there was something funky going on.
There are situations in my calculations where two placement choices have equal amounts of winning sub-games. Initially I thought I could just set an order of preference of my choice for these, but the resulting strategies beat each other when applied to all possible games. If the order of preference did not matter this should not happen.
For the longest time I could not figure out why this happened. I started questioning whether the markov property held in the game (I am still not 100% sure it does).
Enlightenment
At this point I took a few steps back and looked at what would be the correct framework to model this game in. Turns out it can be modelled as a Markov Decision Process. That in itself was not very helpful, but it eventually got me reading about the expectiminimax algorithm. Expectiminimax is a version of minimax for games with chance involved. While I had to modify it a bit for a simultaneous turn game, I implemented it for some subproblems of get 1000, which I could calculate to the bottom.
While implementing it I realised that I again would have to code resolution for when two choices are equally good. While googling a bit about that, I randomly read about Nash Equilibrium, and mixed strategies. I was already aware of most of this, but it suddenly it dawned on me that my game might contain mixed strategies which could effect the outcome my expectiminimax calculation, and which I needed to take into account.
Wrong payoffs propagated in expectiminimax
Indeed, after searching for a bit, I found several cases where a mixed strategy is needed. The example below shows a expectiminimax situation where a mixed strategy is needed to get the best outcome.
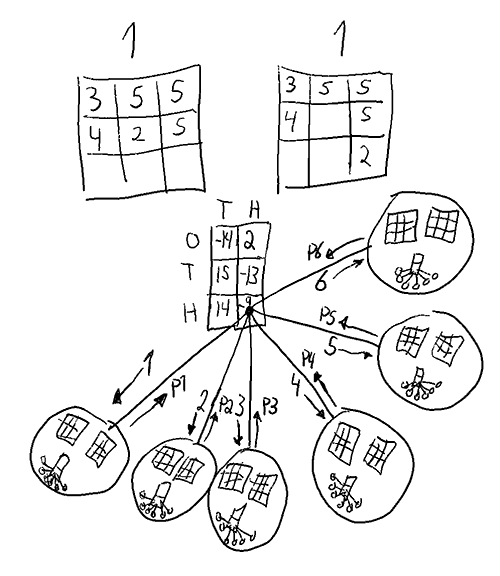
While this exact situation will probably not arise assuming perfect play, the result still might matter since expectiminimax depends on all subgames propagating correct payoffs.
The road ahead
I need to include the support enumeration or theLemke-Howson algorithm for finding nash equlibrium in the placement situations that require it, and then I need to somehow make expectiminimax run for the full game. Currently I can only run expectiminimax (without Lemke-Howson) in reasonable time, for a game which has 6 placements left.
From AI: A modern approach, it seems A/B pruning can be used, but it seems to be less effective on games with chance. I guess it is worth a shot.
Gl hf to me…