Facebook is the only social network I use for anything serious. I wish it was more like the forums from 20-15 years ago, but I digress. Lately my Facebook got filled with more and more Suggested for you nonsense. Previously I used the hide feature on those, and that partly worked for a while, but now it just leads to more and more fringe stuff appearing. Eventually I conjured up some energy to deal with it.
What Stable diffusion should have come up with for the promt: Facebook Suggested for you on a good day.
I do not trust random browser plugins, so I decided to look into writing it myself. Firefox makes that very easy. This small snippet made Facebook acceptable again.
//Stupid flag to only run removal after some time, and not on each observed update
var mut = false;
//Get rid of "Suggested for you", probably needs customization everytime FB adds more divs ;) , worked on 19 Mar 2023!
function removeShit() {
if(mut == true) {
for (const span of document.querySelectorAll("span")) {
if (span.textContent.includes("Suggested for you")) {
console.log("Hide all the nonsense")
//The hardest part of all this is counting all that nesting, what is going on here.
var pr = span.parentElement.parentElement.parentElement.parentElement.parentElement.parentElement.parentElement.parentElement
if(pr.style.display != "none") {
pr.style.display = "none";
}
}
}
} else {
//console.log("No crap seen yet")
}
}
//Observe the entire doc
const targetNode = document
//Observe all the crap
const config = { attributes: true, childList: true, subtree: true };
// Execute on observe
const callback = (mutationList, observer) => {
for (const mutation of mutationList) {
if (mutation.type === "childList") {
mut=true
} else if (mutation.type === "attributes") {
mut=true
}
}
};
const observer = new MutationObserver(callback);
// Start observing
observer.observe(targetNode, config);
//Interval to check for site changes and remove stuff.
const intervalID = setInterval(removeShit, 100);
As always, use at your own peril.
Facebook will still spice it all up with the ineffable timeline ordering, and still eats all the datas.
I have been hacking on some libcamera experiment, and this time I had the misfortune to have to try and use a Jetbrains product in a local VM and on the host system at the same time.
Since it is practical I was using UTM shared networking, but that had the unfortunate side effect that Clion in the VM and IntelliJ on the host detected each other and refused to both be open at the same time. Incredibly annoying…
Googling I figured out that if you use the same username in the VM and on the host it will all work out. I got more and more confused as to why this feature exists, but a glimmer of hope emerged. I was not ready to change user in the VM or on the host though, since I had used some time to set up that user.
Thankfully, this detection feature uses the JVM system property user.name, to lookup the user, so adding -Duser.name=<host username> to the clion64.vmoptions file made it all work out.
A few days ago I started up an Ubuntu VM to run some silly experiment. Suddenly I needed a bit more space though, and instead of creating a new disk I decided to expand the current one instead. This took some time to figure out, so posting it here for my future self and others who possibly might want to do this.
Since there was nothing of real importance on this VM, I did most steps on the VM while it was running. Take backups if you attempt this and care about your data, I am not sure all of it is safe.
I am running QEMU using UTM on my M1 mac, and the .qcow2 files get put somewhere deep in the users Library folder by default. Once I found the file, I shut down the VM and did this on the host:
qemu-img resize disk-0.qcow2 50G
Then I started the VM, installed gparted and expanded the partition. df still reported the disk to be 90% full though. Eventually I figured that I also needed to expand the logical volume. The command to do this was:
But still df reported the volume to be full. Seems the ext4 filesystem also needs to be expanded. This did the job:
sudo resize2fs /dev/mapper/<volume name>
Finally df reports lots of free space! Sweet!
At the beginning, I shut down the VM before I did the first resizing of the .qcow2 file. I am not sure that was necessary. The next time I need to expand a disk on an unimportant VM, I will try without shutting it down for sure.
TLDR; Never use field Injection in Spring, scope APIs well, and do not mock value objects.
As this story starts, I was the system responsible for an old application which was being replaced. The replacing application was made by an external team (largely outsourced and supposedly seniors), but once in production, the new system would become part of the responsibility of the maintenance team I was on.
Beginning this transition, I started looking at the new system. My initial impression was good. The database schema was cleaned up compared to the old system. The project seemed more organized. It had a DB migrations system set up. A big improvement compared to what it was replacing.
To get more accustomed to new application, I started looking at simple bugs. My first bug was a simple mapping error towards an external system. I quickly found the offending code, and changed the implementation. My change should have broken some tests, but instead of assertion failures I kept getting weird NPEs from data that could not possibly be null.
Testing the tests
Weirded out, I started looking into the test suite. The tests all looked something like this:
class MapperTest {
@InjectMocks
Mapper mapper;
@Mock
SubMapper mockedSubMapper;
@Mock
SubMapper2 mockedSubMapper2;
@Mock
NuValue next;
@Mock
Value value;
public void testMock() {
when(value.getFoo()).thenReturn("Foo");
when(value.getBar()).thenReturn("Bar");
when(mockedSubMapper.map(any())).thenReturn(next);
when(mockedSubMapper2.map(any())).thenReturn(next);
NuValue nu = mapper.mapMaiStuff(value);
assertNonNull(nu);
}
}
What does this do:
@InjectMocks will when hit by the MockitoRunner, instantiate the @InjectMocks annotated class, grab the relevant @Mock classes and add them to the @InjectMocks annotated one.
All the when().thenReturn() then create the mock behavior as well as build return values. Essential re implementing or ignoring most of the behavior that should be under test.
Even this simplified example is hard to read, but the tests I was dealing with, had when() mock statements that went on and on, and there were from 2-10 mocked dependencies, and several levels of mocked value objects.
What does this have to do with dependency injection and Spring? Is it not excessive mocking that is the problem?
The responsibility for this mess lies with the developers, but I think it is interesting to try to understand how they ended up in this dark alley. I think mocking is a symptom and not a cause here.
Much of the cause in my opinion lies with Spring. Spring dependency injection can be done by constructor, setter, or field injection. The classes I had trouble with all used field injection. They looked a lot like this.
@Component
class Mapper {
@Inject
private SubMapper subMapper;
@Inject
private SubMapper1 subMapper1;
public NuValue map(AllTheData data)
String v1 = subMapper.map(data);
String v2 = subMapper1.map(data);
return new NuValue(v1,v2);
}
}
The mocking was done because the class itself can not be properly constructed without some magic. The only way to test here is to either fire up Spring (slow) or use something to reach in and set the dependencies. One way is to use Mockito @InjectMocks.
While this partly explains what happened, it does not explain why the value objects were mocked.
I think the value objects were mocked because some of these methods take very large value objects as input. The code under test only reads a very small part of the huge object. This means the test now needs to create that huge value object, which is tedious. So someone came up with mocking the value objects, and rewiring them using Mockito. (This essentially means the value object has been re implemented).
Both these practices seemed to have been adopted as convention. The result was:
Tests that were clinging to the existing class structure, but that did not test anything useful. Mostly they tested themselves and Mockito. They tried to test some useful cases though, so they could not just be deleted.
Extremely low development velocity. Every change to one of these classes caused a chain reaction of tests that had to be either hacked so that they compiled, or fully rewritten. Fully rewriting a test often caused other chain reactions of changes that were really hard to manage.
It took close to half a year to get most of this code in an halfway acceptable shape with decent test coverage.
Most of these classes were refactored to pure functions. The classes were mostly transforming data from one representation to another. There was no need to involve Spring at all.
For some reason whenever I see Spring projects, they all manage way too much using Spring. My hypothesis is that once an annotation based DI framework is in use, using it becomes an alluring path of least resistance. It is so easy to copy an existing class with @Component, and hack from there, instead of thinking about the design.
Closing thoughts
This and other experience has fueled a strong skepticism against annotation based dependency injection frameworks in me. I have found that they are not needed most of the time. They can be used responsibly, but are they worth it? In my experience they create just as many problems as they solve.
To be fair, Spring seems to not use field injection in their documentation anymore. That said, Spring does define what can be done. Field injection at best saves 3-5 lines of code for each dependency, and it is never the right thing to do. Spring should just crash at startup if it detects field injection, that would be sane.
As far as Mockito goes, I think it was mostly innocent in this story, though I do think @InjectMocks should log warnings when it has to break the class contract to add mocks. During all of this, I also had the displeasure to learn what Mockito.RETURNS_DEEP_STUBS does. The documentation has this gem though (A a redeeming factor in my eyes.):
WARNING: This feature should rarely be required for regular clean code! Leave it for legacy code. Mocking a mock to return a mock, to return a mock, (…), to return something meaningful hints at violation of Law of Demeter or mocking a value object (a well known anti-pattern).
Good quote I’ve seen one day on the web: every time a mock returns a mock a fairy dies.
My good friend Feda Curic recently came to me and wanted to make something together during his parental leave. At first we started out with something a bit too ambitious (for the time we had set aside), but then his wife came up with a great idea we could finish in our limited amount of time.
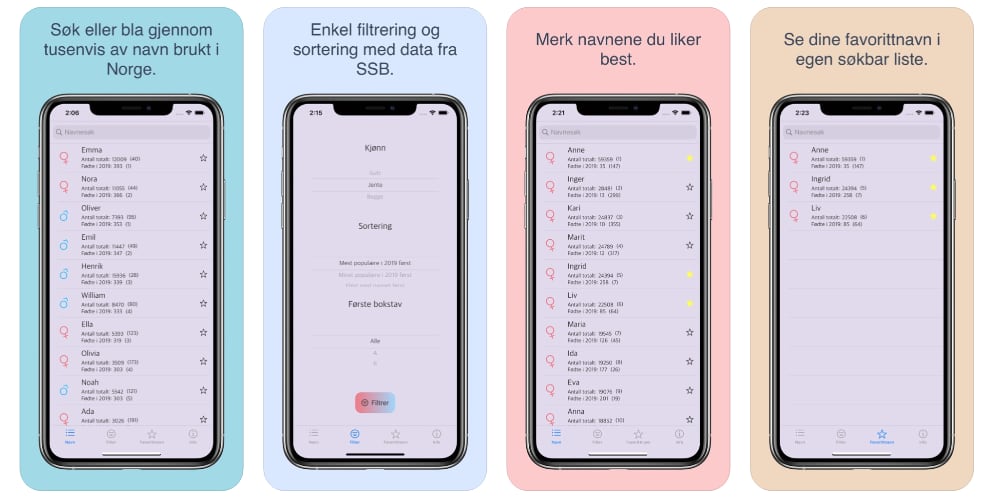
She wanted an app where you could quickly look up names for babies. Here in Norway Statistisk sentralbyrå (SSB) has statistics for all names used 4 or more times. The SSBs user interface leaves something to be desired though. It is either small lists containing some names, or a name search, where you input the exact name, and then get statistics about that specific name.
The SSB interface is not at all useful for exploratory search for names. In Babynavnvelgeren (the app we made) we have a lightning fast interactive search and filtering options. The data is available locally in the app, so it mostly works offline as well.
Babynavnvelgeren makes searching for names easy and fun. My 8 year old daughter loves searching while sorting for the least popular names. She found some very interesting ones like:
Sau – Sheep in Norwegian.
Lillebil – I initially thought this was a bug for sure, but it is a name. My daughter finds it hilarious (“Lille” means small and “bil” is car in Norwegian).
More generally I think Interactivity and responsiveness is essential for exploration, and the process of exploration often leads to accidental discoveries and new hypothesis building. UIs which support this kind of interactivity are very useful in my experience, and I think more applications/data providers should have this in mind when presenting their data.
I also think there is a lot of low hanging fruit in this space, and small improvements in interactivity often cause massive increases in efficiency. For Norwegian names, Babynavnvelgeren has got you covered. Go get it!
When Kotlin 1.0 came out, I tried type-safe builders a bit, with mixed feelings. They are a great way to create simple declarative DSLs for building hierarchies, but using them used to be quite a pain.
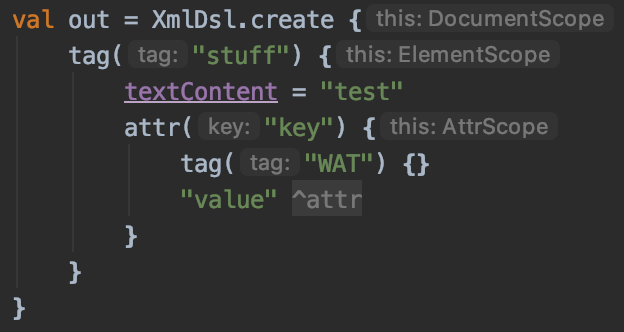
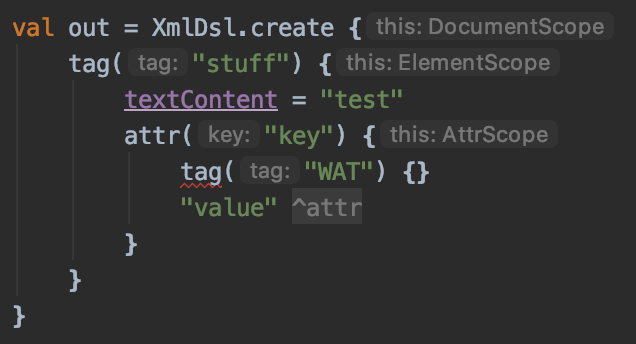
The main problem was that as the nesting got deeper, the DSL API would include methods from all the scopes. Only some of those methods were usable in the current scope. This was infuriating to use, since if you used a method in the wrong scope, it would often cause wrong behavior instead of an error. Here is an example using a simple XML DSL:
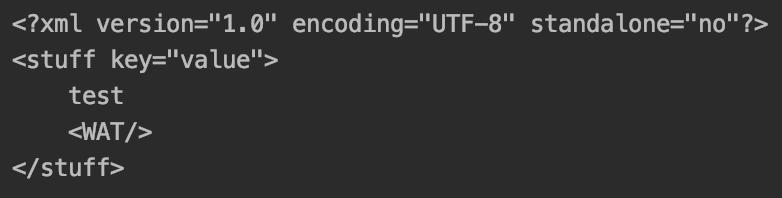
A tag inside an attribute, WAT…
It makes no sense to have a tag inside an attribute, but this would not fail, but instead cause the below XML document to be created. It is valid XML, but probably not what was intended given the above nesting.
Yesterday I needed to do create some XML, and I remembered type-safe builders to be great for this. I quickly whipped together the simple API above for that, but again was confronted with the scoping problem. Initially I figured out a very hacky way to provide nice errors at runtime, but then I thankfully read up on the Kotlin documentation, and in Kotlin 1.1, the @DslMarker annotation was added to ensure that only methods in the current builder scope is visible.
This moves type-safe builders from good to awesome in my book.
With @DslMarker annotation, the tag is not visible in the attribute scope, and this nonsense fails to compile.
I am late to the party, but this feels like a change that is easy to miss, and that does not get enough attention. Superb of the Kotlin team to address things like these!
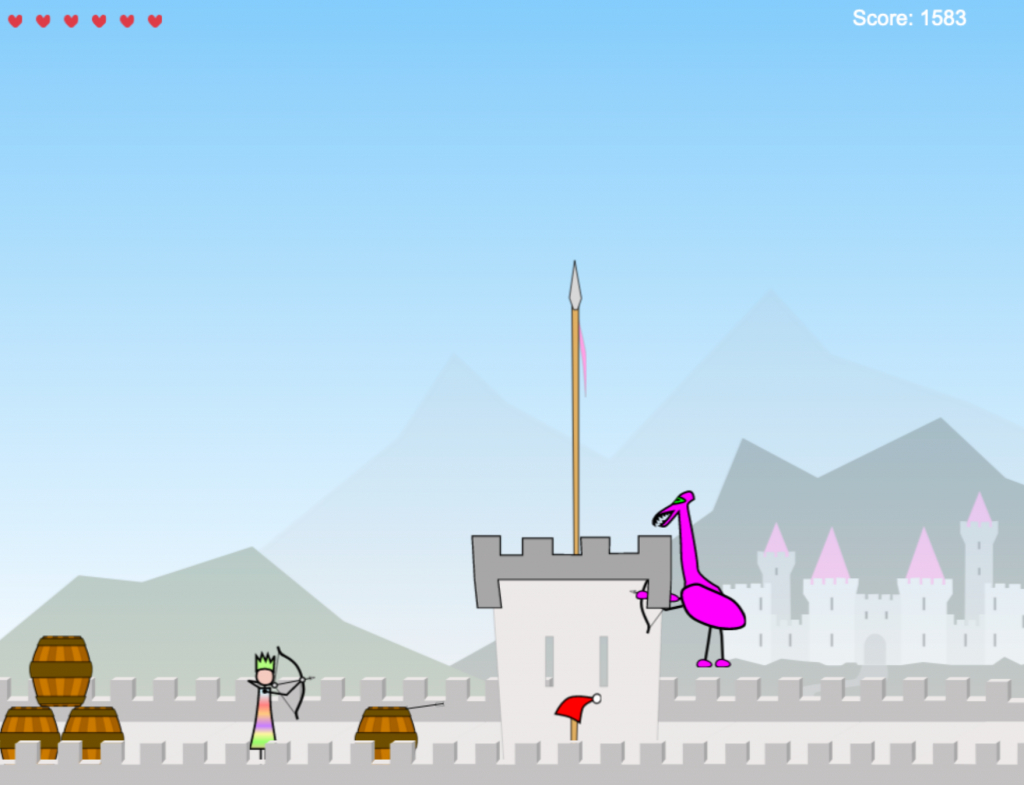
TLDR; I’m writing a coop multiplayer game with my daughter, this is the current result! Works in Firefox and Chrome. Use arrows to move and space to fire. Share a URL to play with a friend.
Some years ago, my daughter figured out I made some computer games, and she even played one of them quite a bit. After a while she wanted something new, and we figured we’ll make a game together. She would draw concepts and come up with ideas, and I would try to make them happen in game.
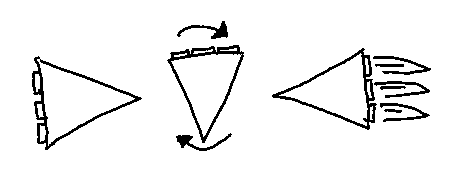
The initial concepts she drew were these:
We then together made them into vector with some modifications.
A princess and a giraffe… I guess
Tips on kid friendly vector drawing programs would be very much appreciated, throw me an email or post a comment. We used Sketch, but Sketch is a bit overwhelming and distracting with all its features. I want a program which only have bezier patches and transformations on them, as well as fill, stroke and possibly opacity settings.
Going from concepts to a prototype
I had been wanting to try compile to JS with Kotlin for a while, so I started a project in IntelliJ and quickly threw something together using a plain HTLM5 Canvas.
We drew some more concepts, and after some evenings implementing we had an infinite randomly generated castle, an arrow firing princess, a hyperactive bow carrying giraffe, and a bunch of collision detection bugs (yay for rolling your own).
Wriggling out of hard requirements
After a lot of fun triggering bugs, my daughter came up with some new requirements.
I want to play with my friends, and we should all be princesses!
These are sort of hard to implement, disregarding networking, it would mean a total rewrite of how the world generation and camera worked. It would also need a solution for how to avoid someone getting stuck due to the camera movement of others and so on.
Those giraffes are in for a surprise.
After some bargaining we made some new concepts, and we agreed to add a player controlled cloud, and a bunch of new giraffes.
Adding networking
For me this meant that I would need to add some kind of networking to the game. For browser games, the choices are:
Communicate with a server using WebSocketand have that relay state, or run the game on the server.
Negotiate a WebRTC datachannel, and send communication directly between the browsers.
Have players install a browser extension like netcode.io,and use it instead of WebSocket.
Since the game is cooperative, there is little reason to run the game on a server. Actually I really, really do not want to run the game on server, for a bunch of reasons, mostly for abuse and scaling troubles.
Using a server as a relay of state or input is also a bit funky, since it will introduce a lot of unnecessary latency. Since I am also willing to sacrifice some poor kids behind a symmetric NAT, I decided for option 2 and I have not regretted that.
I was cautious about doing this initially, since I had read this Gaffer on Games post which deemed WebRTC too complex, though that was in the context of server based architectures.
Having some more experience with WebRTC now, I agree a bit about the complexity, though I think it has gotten way better, especially with a more stable standard and more complete alternative implementations like rawrtc. I also ♥ how WebRTC abstracts away most of the P2P complications behind a very nice API.
Autorativepeer or GGPO?
To share state in the game, I needed to come up with an architecture for networking. Initially I evaluated using something like GGPO, but in the end I chose to go with using the princess peer as an autorative peer, and sync the state to the cloud playing peer continuously, while the cloud peer only sends input. I chose this mostly for simplicity and time constraints. Since the game is cooperative, a lack of fairness is also not really a problem.
For the amount of work i put in, I am very pleased with how the networking worked out. Right now it is not tuned at all, just JSON over the datachannel, but even without tuning and no extra speculative integration, it has worked fairly well.
Where to go from here.
While the game is in a state of continuous updates, I think it is mostly just going to be small changes from now on. Maybe some sound effects and new graphics when we feel like it.
Rendering is currently also quite slow, and takes a lot of the frame budget. I would like to migrate to a framework with a WebGL based renderer. But sadly that seems like quite a bit of work, mostly due to using SVGs for graphics.
For future projects game projects, I will for sure start with a WebGL based framework, or possibly Unity tiny, and raster based images.
That is all for now, go and see how far you can get in our game!
For a quite a while, I have wanted to try and create simple touch based interface for a 2D spaceship game. I want to allow the player to simply drag anywhere on the screen, and the spaceship moves to that position and direction in an efficient manner. Ideally the most efficient manner.
Spaceships in 2D games usually have one main engine that allows forward thrust, and some that allow rotation around the ships center of mass.
Moving from point A to B efficiently (in minimal time) is not trivial with such constraints, as changes to direction and thrust may have huge consequences for later possible movements due to inertia.
So instead of looking at the full A to B problem immediately, I wanted to look at something simpler first, namely to go from having velocity \(v_0\) and pointing in direction \(\theta_0\) to have 0 velocity as fast as possible.
The idea I use originally came from talking to a colleague, but something very similar sounding is mentioned in planning algorithms, though examples always seems to involve driftless systems. Anyway, my current approach involves these known quantities and assumptions:
\(a\) – Acceleration – The ship can only accelerate by a constant amount, and acceleration turns on and off instantly.
\(s\) – Turn speed – rotating the ship requires no acceleration, and the ship has constant rotation rate.
\(\theta_0\) – Initial orientation.
\(v_0\) – Initial velocity
These quantities allow me to find a legal, but very suboptimal way to stop. It simply involves to turn the ship to face its velocity vector, and then accelerate until it stops. Both the time needed to turn the ship \(t_a\) and the time \(t_m\) needed to turn and reverse the velocity are easy to calculate.
Turn until facing velocity and initiate burn at time \(t_a\). At \(t_m\) the ship has velocity 0.
It is also easy to see that this is suboptimal, it would clearly be faster, to start burning some time before the turn is fully completed, but the question is when to start the burn.
To allow for this freedom in my model, I therefore introduce a third time variable \(t_s\). \(t_s\) is the time to start turning and accelerating at the same time. \(t_a\) now becomes the time when I stop turning and only accelerate.
Turn and initiate burn after \(t_s\) time, at \(t_a\) time only accelerate. At \(t_m\) the ship has velocity 0.
Given these intervals, two integrals describe how the velocity will change when \(t_s\), \(t_a\) and \(t_m\) vary.
The most efficient solution to this problem, is the \(t_s\), \(t_a\) and \(t_m\) triplet with the lowest value for \(t_m\).
This information allows me to formulate this as a optimization problem.
Since I want to minimise \(t_m\), the objective function simply becomes \({t_m}^2\).
This is subject to the two equality constraints given.
Since the objective and constraints are non-linear, I plug i into Optizelle which is a framework for solving non-linear optimization problems.
The implementation can be found on github, it uses autograd, to calculate derivatives and hessians. This is an incredible time saver since calculating 9 combinations of partial derivatives would have been a major pain, not to mention having to recalculate them whenever I did something wrong.
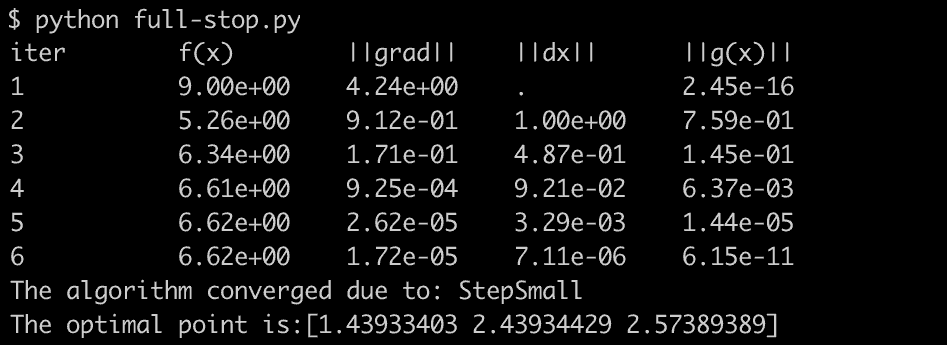
Running the program with inputs \(a=2.0\), \(\theta_0=0\), \(v_0=[2,0]\) and \(s=\frac{\pi}{2}\) returns:
The optimal point vector contains the values for \(t_s\),\(t_a\) and \(t_m\). This means that for a ship with the given input, it should start turning immediately, then start the burn after approximately 1.43 seconds, stop turning and only accelerate at 2.43 and finally be at rest after 2.57 seconds, approximately 0.43 seconds faster then the naive version.
To test the result, I implemented a quick and dirty javascript program that simulates these choices and renders to a canvas:
Sometimes the ships end up drifting a bit after the simulation has finished. This is due to the discrete nature of the simulation not perfectly emulating the continuous solution (I do not integrate rotation analytically in the simulation). This could also have been a problem if I applied this style of planning to a game that did the same, from the simulation above it looks negligible though, which is great!
I am very happy with this result, it seems like it could work for the larger problem as well. The next step I’ll try, is to tackle some specific cases of moving from point A to B efficiently. For those cases there will be many more time variables involved, and possibly many constellations of safe initial starting points as well as possible freedoms to introduce in the model. It will be interesting to see how that works out.
My expectiminimax based solution works well for a game with random elements and perfect information, but it is not very useful for a game with imperfect information. Get1000 is played simultaneously by the players, and the opponents choices are hidden until the end of the game.
This meant I had to go back to find a new strategy for solving the game. I decided to try and find the correct brute force way first, and then see if that could be made faster in some way.
Exploring brute force
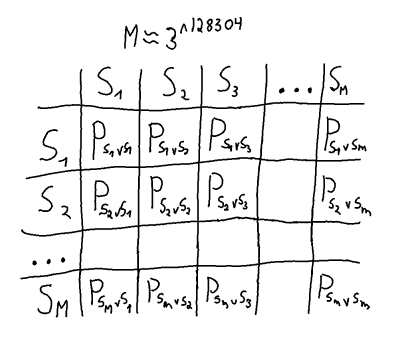
A solution to the game involves finding a Nash equilibrium from all the pure strategies of the game. A brute force solution could be done by creating a matrix where all pure strategies are pitted against all the other pure strategies.
The full payoff matrix needed for a normal form brute force solution.
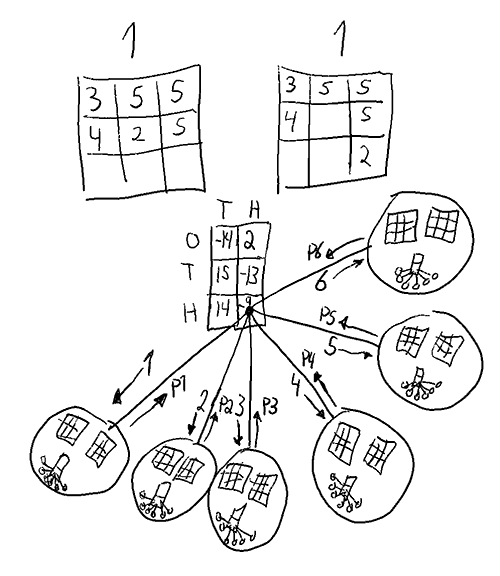
A strategy here refers to a function which given any game state gives a Get1000 placement . Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.
A gamestate
A gamestate can be represented as the current number (in this case 1), the entries in hundres (7), tens (5) and ones (12) as well as the amount of free positions for hundreds (1), tens (2), ones(2).
The total amount of such states is but in at least the choice is forced. This means there are at most. relevant states, probably quite a bit fewer.
Each state has at most 3 choices, therefore there is an upper bound of unique pure strategies.
This is of course not that helpful, since a matrix is enormous, and for each cell in the matrix all possible games would have to be played to find the payoff for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
Subgame perfection and backwards induction
Modeling this in normal form as above seemed to get me nowhere, I therefore turned to extensive form, and something called subgame-perfect nash equilibria, and backwards induction. In the normal form solution I need to look at all possible strategies. Using subgame perfection, I hoped to get away with only looking at a very small subset.
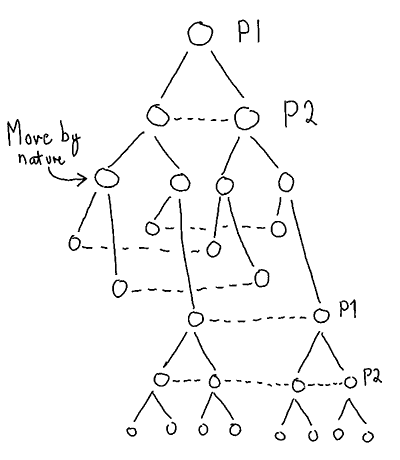
While this sounds straighforward in theory, I found it quite hard to figure out where my information sets are, and whether I could consider each choice node in Get1000 a subgame. After struggling for a while, I ended up with an extensive form structure looking like this. Players are P1 and P2, and “move by nature” is the dice roll.
Extensive form of a game with the same structure as Get1000. As players do their choices, the information sets get larger and larger. Since the “moves by nature” are known by all, they do not increase the information sets.
This structure means that only the roots of the tree are subgames, since all other nodes are part of larger information sets.
Attempting backwards induction
The above structure means that it is not practical to naively use subgame perfection and backwards induction to solve the game, but taking inspiration from it could still be useful to get a good strategy.
The algorithm for subgame perfection goes like this:
Consider the final subgames (those with no further subgames), pick a Nash equilibrium as solution there.
When considering the next subgames up the tree, the payoffs in the subgames already considered are used to create the payoff matrix.
Iterate step 2 until the root node of the extensive form tree is reached.
To get something working, I pretend that the other player is at the same state as me always. This means I can only focus on the branches below that state. To keep memory in check i also recalculate payoffs instead of storing the result for each combination of states and games. The final algorithm I ended up with works like this:
Consider the final subgames and pick a Nash equilibrium as solution.
When looking at subgames higher up the tree, I use the choices (not payoffs) computed in 1, and use those choices to play out the game. Then I compare end results to get the payoff matrix for that subgame.
As before, I iterate step 2 until I reach the root node.
This seems intuitively pretty reasonable.
Experimental results
The above method gives me a strategy that partly takes the imperfect information nature of the game into account. At many states it detected mixed strategies that had much higher payoffs compared to the pure versions. The strategies smashes all my previous best strategies by winning 1.75% more games.
The mixed strategy seems to play even more aggressively for results close to a 1000, and allowing heavy overshoot.
At this point, I was not really sure how to approach the game in a better way. In fact I was pretty ready to admin defeat for quite some time. Of course, immediately after i wrote that, I found this thesis, and this report.
For quite some time I have been trying to completely solve the Get 1000 game. More specifically I am trying to find the strategy in a 1 on 1 game of Get 1000 that maximises the chance to win.
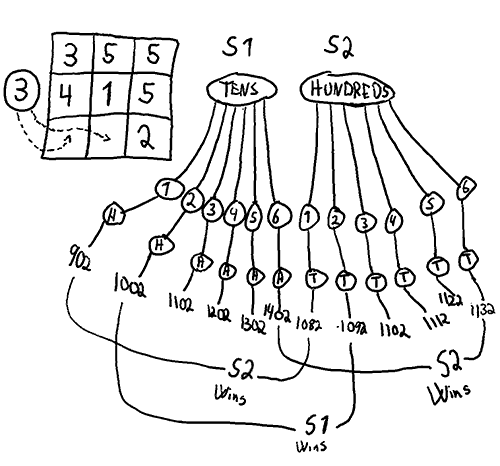
Analysis of a game with one choice left. If I analyse this sub-game using expected value, I return the average of the distances to 1000. In this case 184 for strategy 1 (S1) and 107 for strategy 2 (S2). This is the wrong metric though, a better metric (if the goal is to win in a 1 on 1 game) is to count wins for each strategy. In this case 1 draw, 1 win for strategy 1 and 4 wins for strategy 2.
Solving for expected value rather then winning
My initial attempt at solving the game failed spectacularity, since I attempted to solve the game by minimising the average distance of the expected value to a 1000. This is an easy to compute strategy (using a sort of bottom up dynamic programming, where I start with the easy sub-games above, and calculate backwards to the top), but it is the wrong goal. This leads to a strategy minimising the distance to 1000 on average. This interestingly enough differs quite a lot from the goal I wanted to solve, which was to maximise the chance to win any 1 on 1 game.
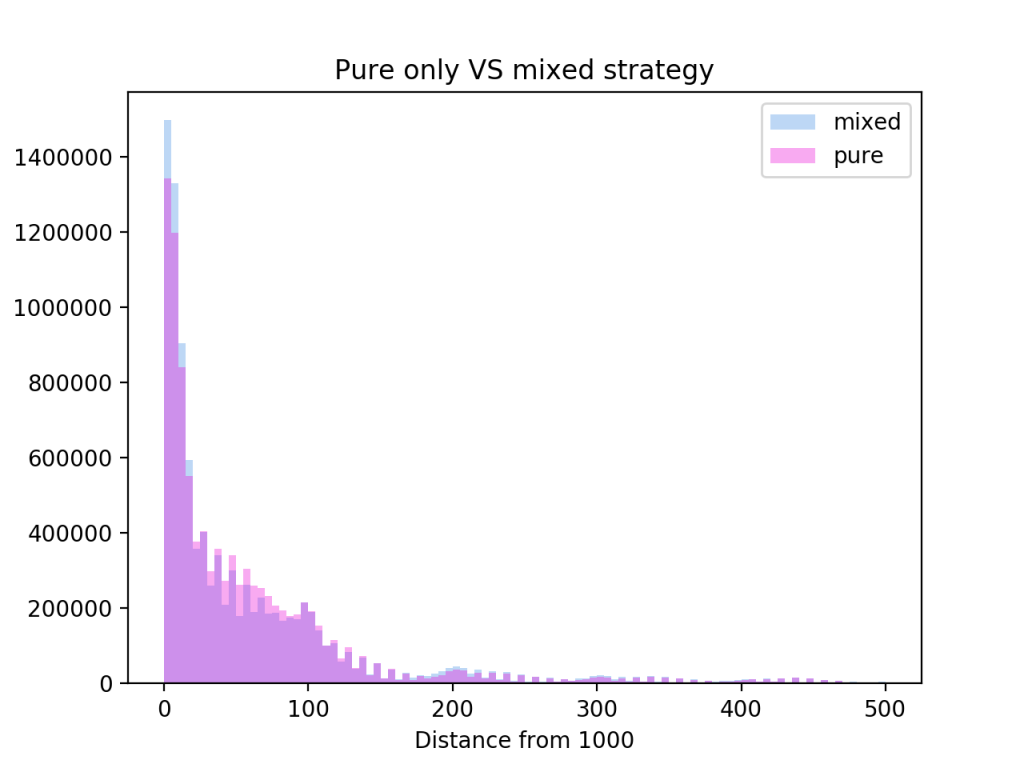
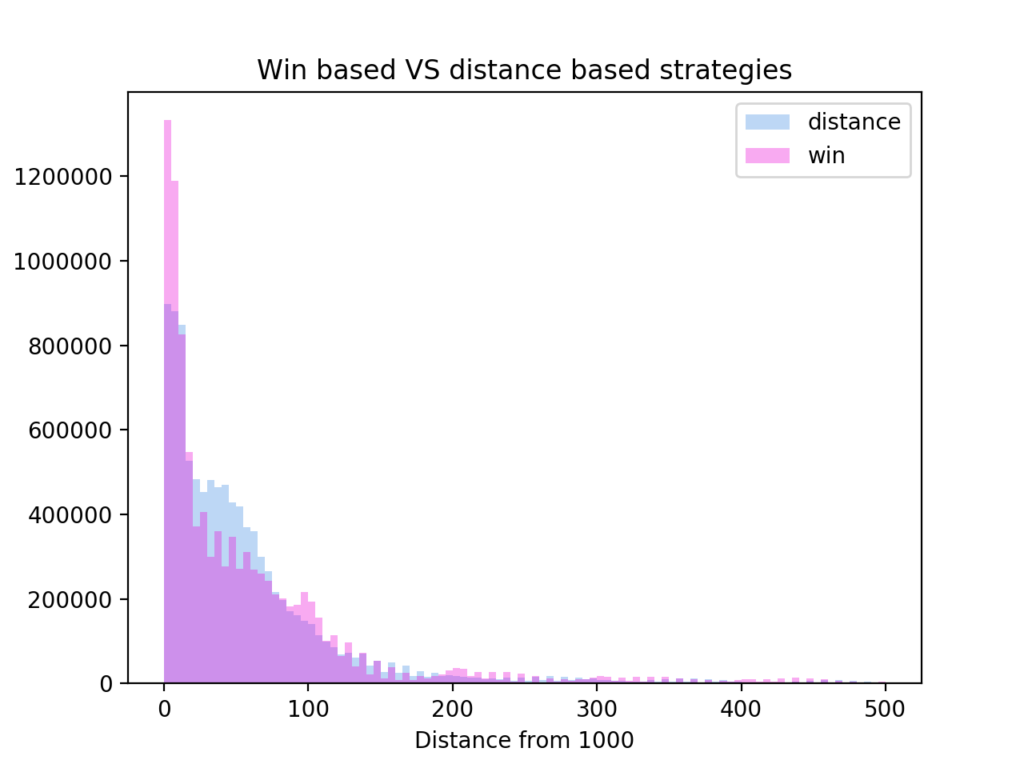
The strategy that bases itself of minimising the distance to 1000 curiously has a big lump of results around a distance of 50, while the win based strategy has more games at distance of 0 and 100, as well as more games with very heavy over or undershoot.
Since Get 1000 is quite small I can calculate how much the two strategies differ by running all possible games. Above is the result of such a calculation. The two strategies draw 41.2% of the time, while the win based wins 30.8% and the distance based wins 28% of the time.
Trouble with situations where choices are equally good
After figuring out I had the wrong goal, I found a way to create a strategy based on wins rather than expected value (this is much harder to compute, even using the same bottom up approach, since it is not possible to collapse results to an average, and ever growing lists of results must be compared). These strategies I suspect are very close to optimal, but there was something funky going on.
There are situations in my calculations where two placement choices have equal amounts of winning sub-games. Initially I thought I could just set an order of preference of my choice for these, but the resulting strategies beat each other when applied to all possible games. If the order of preference did not matter this should not happen.
For the longest time I could not figure out why this happened. I started questioning whether the markov property held in the game (I am still not 100% sure it does).
Enlightenment
At this point I took a few steps back and looked at what would be the correct framework to model this game in. Turns out it can be modelled as a Markov Decision Process. That in itself was not very helpful, but it eventually got me reading about the expectiminimax algorithm. Expectiminimax is a version of minimax for games with chance involved. While I had to modify it a bit for a simultaneous turn game, I implemented it for some subproblems of get 1000, which I could calculate to the bottom.
While implementing it I realised that I again would have to code resolution for when two choices are equally good. While googling a bit about that, I randomly read about Nash Equilibrium, and mixed strategies. I was already aware of most of this, but it suddenly it dawned on me that my game might contain mixed strategies which could effect the outcome my expectiminimax calculation, and which I needed to take into account.
Wrong payoffs propagated in expectiminimax
Indeed, after searching for a bit, I found several cases where a mixed strategy is needed. The example below shows a expectiminimax situation where a mixed strategy is needed to get the best outcome.
A Get 1000 situation as solved by expectiminimax. The two games on top are the current situation for two players. To make a decision in expectiminimax we must then compute the payoff matrix by recursively analysing all possible sub-games until the end (returning expected payoffs), and then solve the payoff matrix. Using the solver here, this particular sub-game has the payoff of -98/39 (- means in favour of player 2). In this situation: Player 1 should play ones at ratio of 23/39 and hundreds 16/39, and player 2 should play tens at a ratio of 11/39 and hundreds 28/39.
While this exact situation will probably not arise assuming perfect play, the result still might matter since expectiminimax depends on all subgames propagating correct payoffs.
The road ahead
I need to include the support enumeration or theLemke-Howson algorithm for finding nash equlibrium in the placement situations that require it, and then I need to somehow make expectiminimax run for the full game. Currently I can only run expectiminimax (without Lemke-Howson) in reasonable time, for a game which has 6 placements left.
From AI: A modern approach, it seems A/B pruning can be used, but it seems to be less effective on games with chance. I guess it is worth a shot.





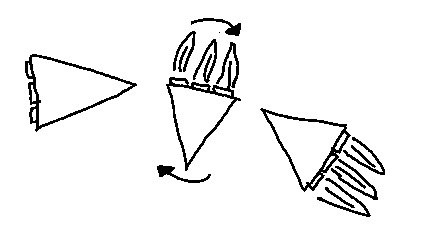

 which given any game state
which given any game state  gives a Get1000 placement
gives a Get1000 placement  . Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.
. Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.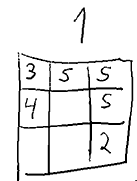
 but in at least
but in at least  the choice is forced. This means there are at most.
the choice is forced. This means there are at most.  relevant states, probably quite a bit fewer.
relevant states, probably quite a bit fewer. unique pure strategies.
unique pure strategies. matrix is enormous, and for each cell in the matrix all possible
matrix is enormous, and for each cell in the matrix all possible  games would have to be played to find the payoff
games would have to be played to find the payoff  for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.